

به نظر میرسد APUهای Instinct MI300A شرکت AMD بهبود عملکرد قابل توجهی را در بارهای کاری HPC در مقایسه با گرافیکهای گسسته سنتی ارائه میدهند.
گفتنیست که APUهای AMD Instinct MI300A تحقق پلتفرم Exascale APU هستند که سالها پیش ساخته شد. ایده این بود که یک گرافیک را به همراه یک پردازنده با کارایی بالا در قالب یک پکیج بسته بندی شود که یک حافظه یکپارچه را پشتیبانی میکند. در HPC، این طرحهای شتابدهنده/کمک پردازنده عملکرد بالاتری در هر وات ارائه میکنند، با این وجود به تعداد زیادی پورت، تنظیم و نگهداری برنامهها با میلیونها خط کد نیاز دارند که میتواند کمی پیچیده باشد. با این حال، به نظر میرسد محققان از دو مدل برنامه نویسی محبوب OpenMP و OpenACC برای استفاده کامل از نسل بعدی APU Juggernaut بهره بردهاند.
در یک مقاله تحقیقاتی با عنوان انتقال برنامههای HPC به AMD Instinct MI300A با استفاده از حافظه یکپارچه و OpenMP، از چارچوب OpenFOAM استفاده شده است که یک کتابخانه متن باز نوشته شده به زبان C++ است:
- ما طرحی از مدل برنامه نویسی APU ارائه میدهیم و سهولت و انعطاف پذیری کدهای پورت کردن در MI300A را با OpenMP نشان خواهیم داد.
- ما روش خود را برای شتاب افزایشی تولید و به طور گسترده در کد صنعت – OpenFOAM – استفاده میکنیم.
از آنجایی که شتاب دهنده AMD Instinct MI300A از یک رابط یکپارچه HBM استفاده میکند، نیاز به تکرار دادهها را از بین میبرد و احتیاجی به تمایز برنامه نویسی بین فضا حافظه میزبان و دستگاه ندارد. علاوه بر این، مجموعه نرم افزار ROCm AMD بهینه سازیهای اضافی را ارائه میدهد که به ترکیب تمام بخشهای APU در یک بسته منسجم و ناهمگن کمک میکند. در ادامه یک خلاصه کوچک در مورد APUهای Instinct MI300A AMD آورده شده است:
- اولین بسته یکپارچه CPU + GPU
- هدف بازار ابر کامپیوترهای Exascale
- AMD MI300A (CPU + GPU یکپارچه)
- 153 میلیارد ترانزیستور
- تا 24 هسته Zen 4
- معماری گرافیکی CDNA 3
- تا 192 گیگابایت حافظه HBM3
- حداکثر 8 تراشه به علاوه 8 پکیج حافظه (فرآیند 5 نانومتری به علاوه 6 نانومتری)
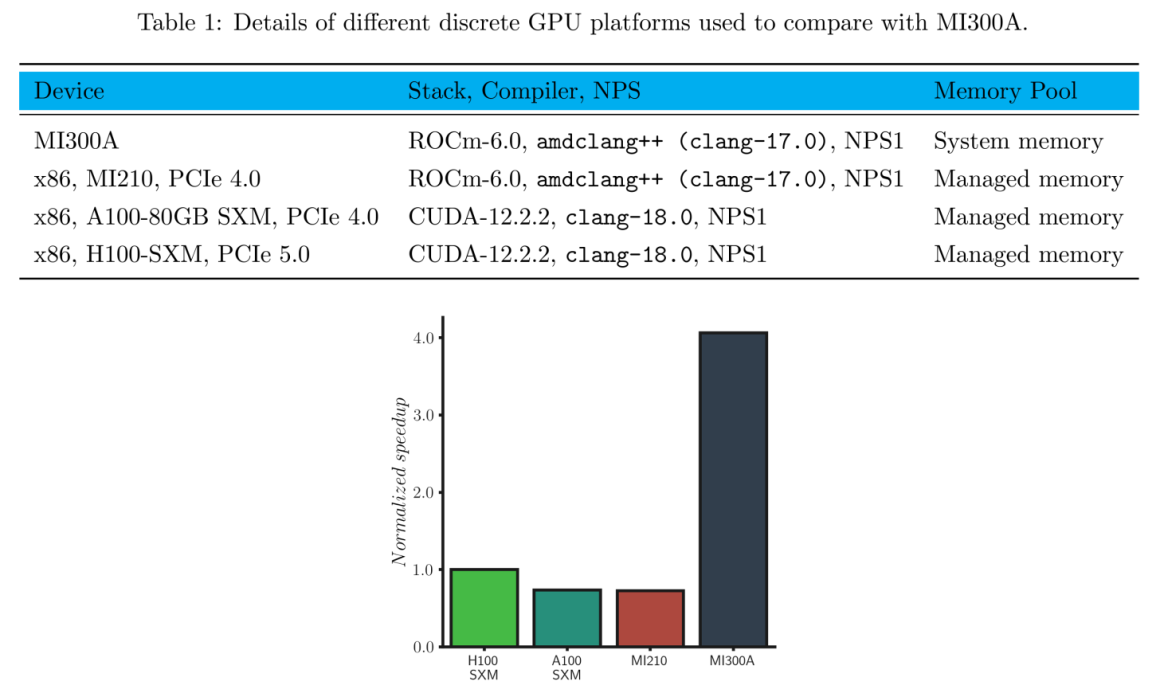
در نتیجه، عملکرد بهرهوری بزرگی را به همراه دارد. در ارزیابی با استفاده از بنچمارک motor bike HPC OpenFOAM، ایپییوهای Instinct MI300A شرکت AMD با سایر پردازندهها از جمله Instinct MI210، شرکت AMD، به علاوه A100 هشتاد گیگابایتی و H100 (80 گیگابایتی) کمپانی انویدیا مقایسه شده است. کارت گرافیکهای شرکت AMD روی پکیج ROCm 6.0 و نسخههای کمپانی انویدیا روی CUDA 12.2.2 اجرا میشدند. بنچمارک به گونهای پیکربندی شده بود که برای 20 مرحله زمانی اجرا شود و میانگین زمان اجرا در هر مرحله زمانی (ثانیه) به عنوان شاخص ارزش (FOM) در نظر گرفته شده است. در تمام سه پیکربندی به جز Instinct MI300A، از یک پردازنده مجزا استفاده شده است که از نظر سوکتی بودن قابل تنظیم بوده و با مدیریت حافظه ناهمگون پیکربندی شده است تا امکان دسترسی به حافظه سیستم توسط گرافیکها و اجرای بنچمارک فراهم شود.
نتایج تستها در رابطه با عملکرد APU Instinct MI300A
در رابطه با تستها میتوان گفت، نتایج با سیستم NVIDIA H100 تطبیق داده شد که بهترین عملکرد گرافیک گسسته را در بین سه تراشه مجزا ارائه میکرد، در نهایت APU Instinct MI300A افزایش 4 برابری نسبت به NVIDIA H100 و همچنین افزایش 5 برابری نسبت به شتابدهنده Instinct MI210 را نشان داد.
- OndGPU، بیش از 65 درصد از زمان، صرف انتقال صفحه میشود: آپدیت جدولهای گرافیکی و کپی کردن دادهها بین میزبان و دستگاه.
- در APU، حافظه فیزیکی یکپارچه مشترک بین هستههای پردازنده و واحدهای محاسباتی گرافیکی، هزینههای اضافی مربوط به انتقال صفحه را به طور کامل حذف میکند و در نتیجه باعث افزایش قابل توجهی عملکرد میشود.
همچنین مشخص شد که AMD Instinct MI300A با یک بسته پردازنده منحصر به فرد Zen 4 که دو برابر سریعتر از یک پردازنده تک سوکتی Zen 4 است که با یک گرافیک مجزا کار میکند. بارگذاری بیش از حد APU MI300A با چندین فرآیند، عملکرد را تا 2 برابر بهبود بخشید (تست شده با 3-6 هسته پردازنده در هر APU) که بسیار بهتر از عدم مقیاس پذیری در پیکربندی dGPU dCPU خواهد بود.
در نتیجه، به نظر میرسد که قابلیتهای محاسباتی Instinct MI300A شرکت AMD در بخش HPC بینظیر خواهد بود. شرکت انویدیا از عملکرد سنتی HPC در نسل بعدی پردازنده بلکول خود فاصله گرفته است، زیرا به نظر میرسد هوش مصنوعی به موضوع داغ این روزها تبدیل شده است. شرکت AMD قصد دارد با شتابدهندههای MI300X و بهروزرسانیهای آیندهاش به این موضوع بپردازد، به نظر میرسد که بخش HPC را بیشتر مورد توجه قرار خواهد داد.